Revisiting Methods to Addressing Selection Bias in the Presence of Missing Data: A Simulation Study
Abstract
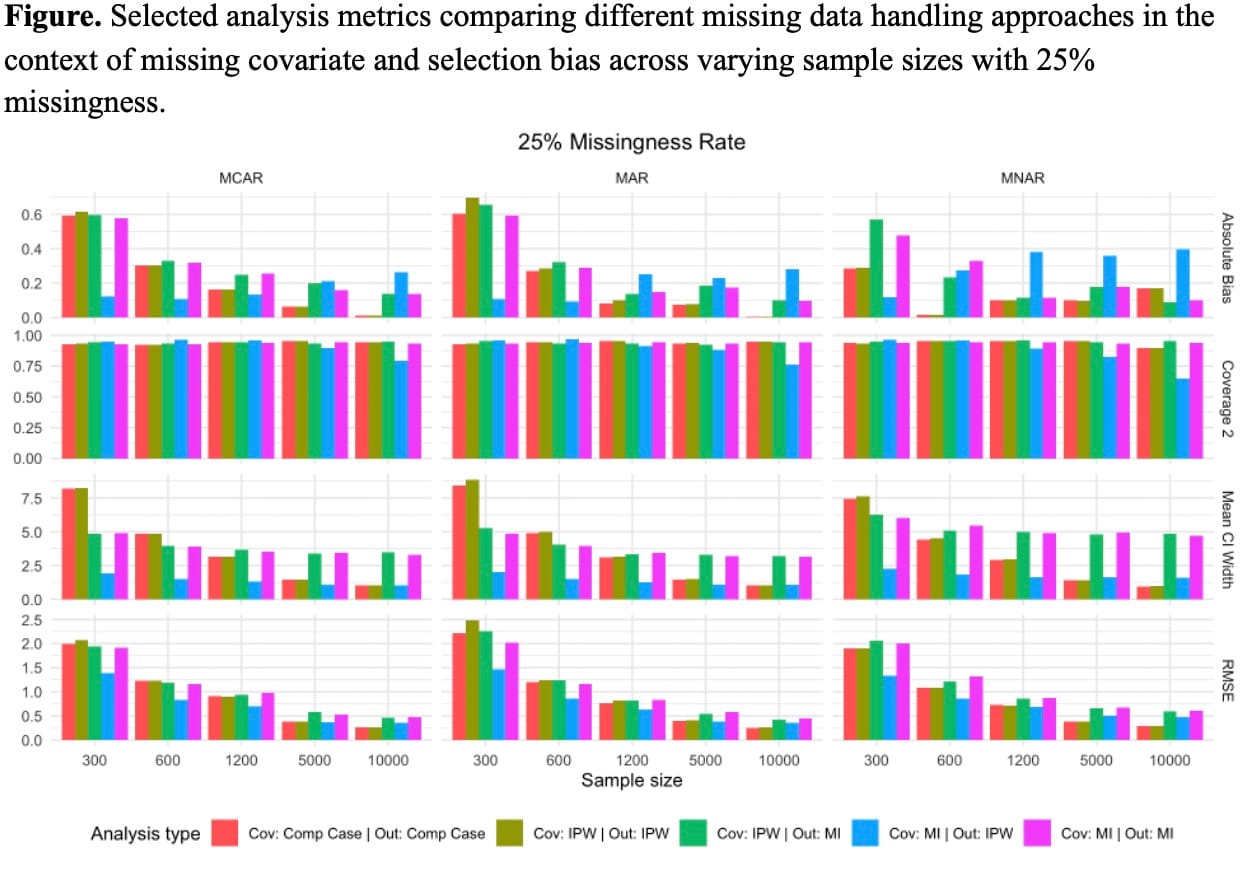
Researchers in epidemiology often encounter both missing covariate data and differential loss to follow-up. It is common practice to use multiple imputation for baseline covariates and inverse probability of censoring weights (IPCW) for the outcome. However, many analytical methods are possible, and their performance remains understudied. This study aimed to evaluate the performance of several analytical methods for simultaneously addressing missing covariate data and loss to follow-up within a simulation framework. We simulated 500 datasets for each combination of sample size (300, 600, 1,200, 5,000, and 10,000), missingness proportions (10%, 25%, and 50%), and three common missing data mechanisms: missing completely at random (MCAR), missing at random (MAR), and missing not at random (MNAR). We compared conditional estimates across five strategies: conditional adjustment of covariates related to the selection and missing data process via complete case analysis; inverse probability weighting (IPW) of both covariate and outcome; IPW for the covariate and multiple imputation (MI) for the outcome; MI for the covariate and IPW for the outcome; and MI for both covariate and outcome. Evaluation metrics included bias, variance, root mean squared error (RMSE), confidence interval (CI) coverage, and CI width. Across all mechanisms and methods, bias and CI width increased with higher missingness and decreased with larger sample sizes. The MI/IPW for the outcome approach exhibited the poorest CI coverage across scenarios; however, coverage improved after adjusting for standard error estimation. Despite coverage limitations, this approach consistently produced the narrowest CIs and lowest RMSE. Epidemiologists must balance the complexity of advanced methods against their performance when addressing missing data. No single approach consistently outperformed others. Sample size and missingness proportion had a greater impact on accuracy and precision than the choice of method.