Optimizing Use of Sparse Internal Validation Data
Abstract
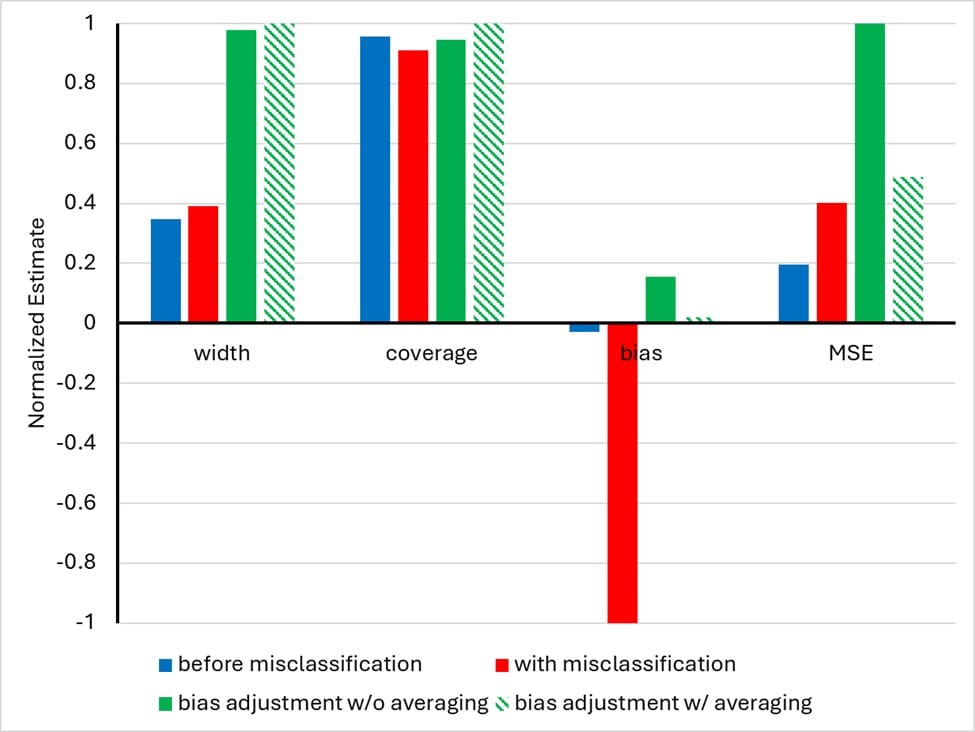
Internal validation sub-studies compare an observed imperfect measurement of an exposure, outcome, or covariate with its gold standard measurement in a sample of the study’s participants. The gold standard measurement is usually expensive or otherwise difficult to collect, so the validation subsample—constrained by the costs—is typically small. To improve the information density of the validation subsample, validation studies usually sample conditional on disease status and the observed (misclassified) measurement rather than using a simple random sample. This conditional sampling allows valid direct estimation of predictive values within cases and non-cases but does not allow valid direct estimation of sensitivity or specificity. Reweighting the validation sample to account for the sampling fractions allows indirect estimation of sensitivity and specificity within cases and non-cases. If non-differential misclassification is expected, weighted averages of these sensitivities and specificities may yield more efficient estimators. We propose, for the first time, to take advantage of these pairs of indirect estimates by averaging them, then recalibrating the estimates of the predictive values used in quantitative bias analysis. Our hypothesis is that the recalibrated predictive values derived from the average of the pairs of independent estimates of sensitivity and specificity will yield better-performing bias adjustments. In our simulation of 10,000 cohorts each with 100,000 iterations of bias adjustments, we show that this new method optimizes the use of sparse validation data for bias adjustment. The averaged estimates yielded lower bias, lower mean squared error, similar simulation interval widths, and better interval coverage. Future work will vary the simulation, extend the method to misclassification involving outcomes, confounders, and modifiers, and combine it with other strategies that might improve the utility of sparse validation data.