Methods/Statistics
Sampling for computational efficiency when conducting analyses in big data Jacqueline E Rudolph* Jacqueline Rudolph Yiyi Zhou Steven Xu Eryka Wentz Maylin Palatino Karine Yenokyan Anyue Ruan Keri Calkins Corinne Joshu Bryan Lau
Background. A challenge to research in big data is the inherent computational intensity of analyses, particularly when using rigorous methods to address biases. We demonstrate the use of sampling methods in big data to estimate parameters using fewer resources. Our motivating question was whether lung cancer incidence differs by HIV status, in nearly 30 million Medicaid beneficiaries.
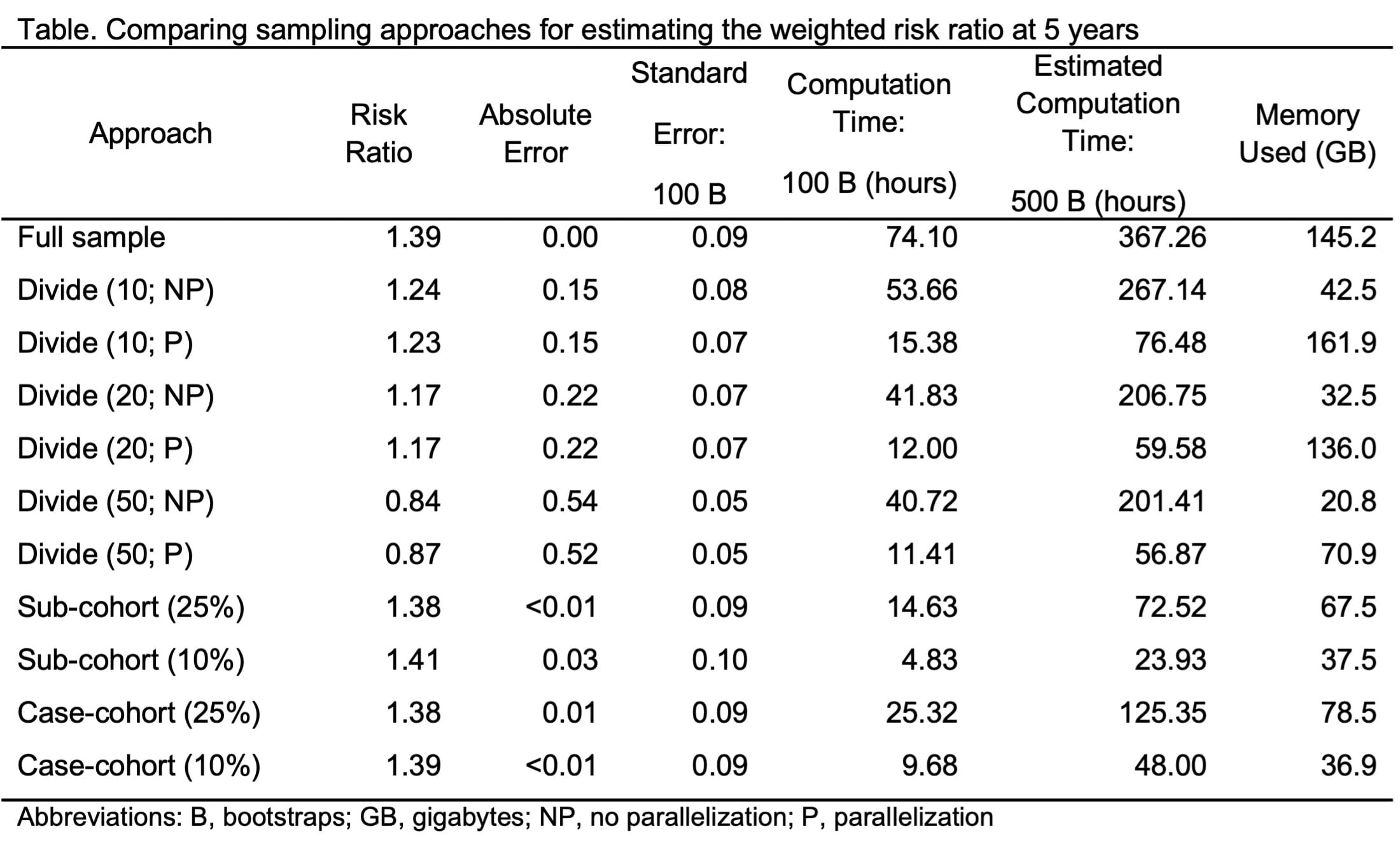
Methods. We built a cohort of Medicaid beneficiaries, aged 18-64, who enrolled 2001-2015 in 14 US states and had 6 months of enrollment (run-in period) with no evidence of cancer. HIV status at baseline was based on presence of an HIV diagnosis during the run-in period. Beneficiaries were followed from baseline until lung cancer diagnosis or censoring. We targeted three parameters: IRR (Poisson model), HR (Cox model), and RR (Kaplan-Meier). We controlled for confounders using inverse probability weights. We ran the analysis using the full sample and several sampling schemes: divide and recombine (10, 20, 50 samples), sub-cohort, and case-cohort. We compared point estimates, standard errors, computation time (hours), and memory used (GB). Analyses were run on one server node with four CPUs, 64 cores, and 660GB of RAM.
Results. We included 29,360,920 beneficiaries, of whom 180,980 beneficiaries (0.6%) had HIV at baseline. We observed 1113 incident lung cancer diagnoses among beneficiaries with HIV and 33,106 among beneficiaries without HIV. Our findings for the risk ratio are summarized in the Table. Inferences were similar across target parameters, although findings obtained using Poisson and Cox modeling required fewer resources (time and memory).
Conclusions. Sub-cohort and case-cohort were more reliable than divide and recombine. The latter performed poorly when estimating the RR and only improved computation time when parallelized (at the cost of memory). Between sub-cohort and case-cohort, including non-sampled cases resulted in increases in computation time and memory.